
EN
傳統(tǒng)的銀行流水審核流程是一種典型的人力密集型作業(yè),其內(nèi)在缺陷在當前業(yè)務需求下日益凸顯,主要體現(xiàn)在以下兩個方面:
1.1 處理效率低下
人工審核涉及對流水單據(jù)的逐行信息錄入、手動計算匯總、跨頁數(shù)據(jù)核對等一系列繁瑣且耗時的操作。處理單份流水的平均時間通常以小時為單位計算,限制了金融機構的業(yè)務處理能力上限。
1.2 風險識別難
面對海量的交易數(shù)據(jù),人工審核出于成本與時效的考慮,往往只能采取抽樣審查的方式,無法實現(xiàn)對所有流水的100%全量覆蓋。這種非全面的審查方式為信貸欺詐、洗錢等違規(guī)行為提供了可乘之機。此外,人工判斷不可避免地受到主觀經(jīng)驗、疲勞程度等因素的影響。
為應對上述挑戰(zhàn),融合了光學字符識別(OCR)、自然語言處理(NLP)與大數(shù)據(jù)分析等技術的易道博識智能銀行流水核查系統(tǒng)應運而生。
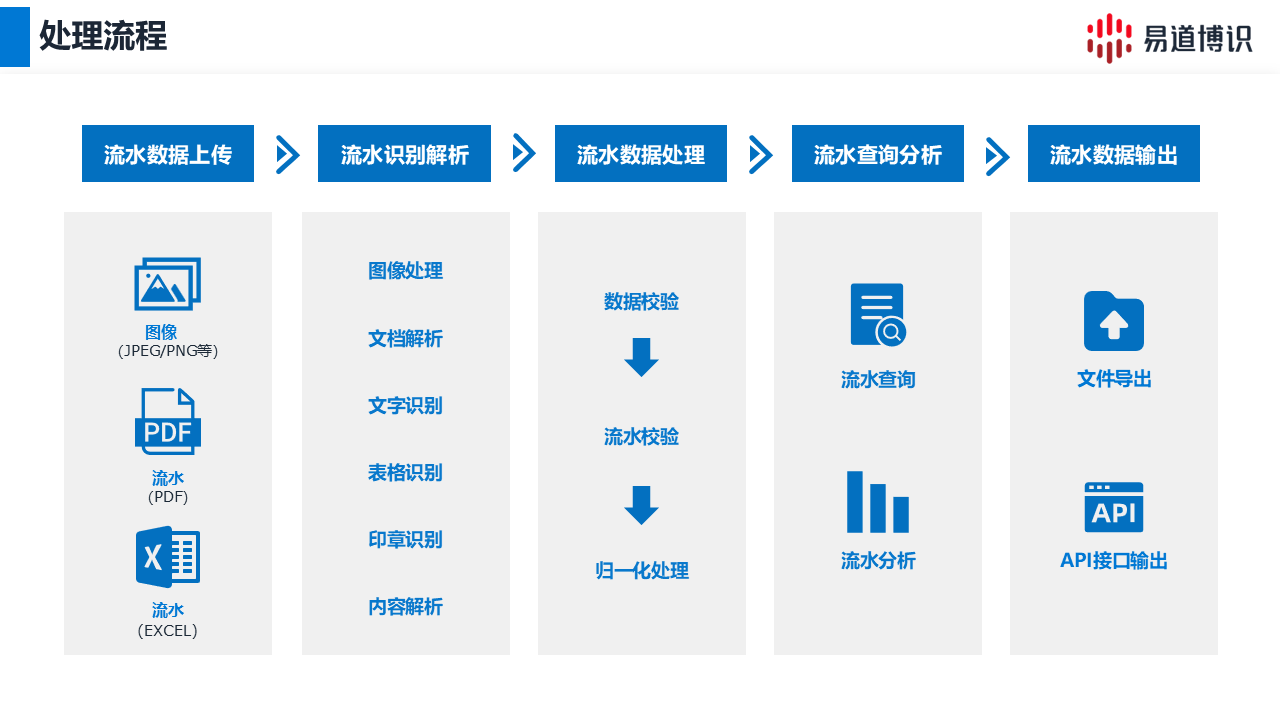
2.1 多源數(shù)據(jù)采集與高度兼容性
系統(tǒng)具備卓越的數(shù)據(jù)接入能力,能夠兼容處理多種格式的銀行流水文件,包括紙質(zhì)文檔的掃描件、電子版PDF文件以及Excel表格等。其數(shù)據(jù)源覆蓋范圍廣泛,可支持國內(nèi)絕大多數(shù)商業(yè)銀行及主流第三方支付平臺的流水單據(jù)格式,確保了數(shù)據(jù)采集的全面性。
2.2 高精度銀行流水識別
智能銀行流水核查系統(tǒng)的核心在于其強大的數(shù)據(jù)處理引擎。
高精度智能識別: 采用行業(yè)領先的光學字符識別(OCR)技術,結合專門針對金融單據(jù)優(yōu)化的識別模型,能夠精準識別各類復雜、非標準版式的流水數(shù)據(jù),即便在圖像質(zhì)量不佳的情況下也能保持較高的識別準確率。
自動化結構化轉換: 系統(tǒng)能自動解析識別出的文本信息,智能提取交易時間、交易對手、交易金額、賬戶余額、摘要等關鍵字段,并將這些非結構化的信息實時轉換為統(tǒng)一、標準的結構化數(shù)據(jù)格式,為后續(xù)的數(shù)據(jù)分析與建模奠定基礎。
2.3 自動化數(shù)據(jù)校驗與清洗
為確保數(shù)據(jù)的準確性與可靠性,系統(tǒng)內(nèi)置了多維度的自動化校驗規(guī)則集。它能夠自動對流水的日期連續(xù)性、交易流水的完整性以及借貸方的賬目平衡關系進行交叉驗證,并對數(shù)據(jù)進行清洗和標準化處理,有效剔除無效或錯誤信息。

智能銀行流水核查系統(tǒng)在金融機構的落地應用,能夠帶來可量化的商業(yè)價值與顯著的戰(zhàn)略競爭優(yōu)勢。
3.1 運營效能的顯著提升
該系統(tǒng)將單個審核任務的處理時間由傳統(tǒng)模式下的小時級大幅縮短至分鐘級,可實現(xiàn)超過90%的綜合運營效率提升。信審人員得以從繁重、重復的數(shù)據(jù)錄入和初級核對工作中解放出來。
3.2 風險識別能力的深度強化
通過對100%全量數(shù)據(jù)進行穿透式分析,系統(tǒng)能夠依據(jù)預設的風險規(guī)則模型,自動識別并預警多種潛在的異常交易模式,為信貸審批和風險定價提供堅實的數(shù)據(jù)依據(jù)。
3.3 合規(guī)性與數(shù)據(jù)可追溯性保障
智能銀行流水核查系統(tǒng)完整地記錄并保存了從原始影像文件到最終結構化數(shù)據(jù)的全流程處理鏈路。這一特性確保了每一項分析結果都具備完整的可追溯性,能夠有源可溯、有據(jù)可查。





